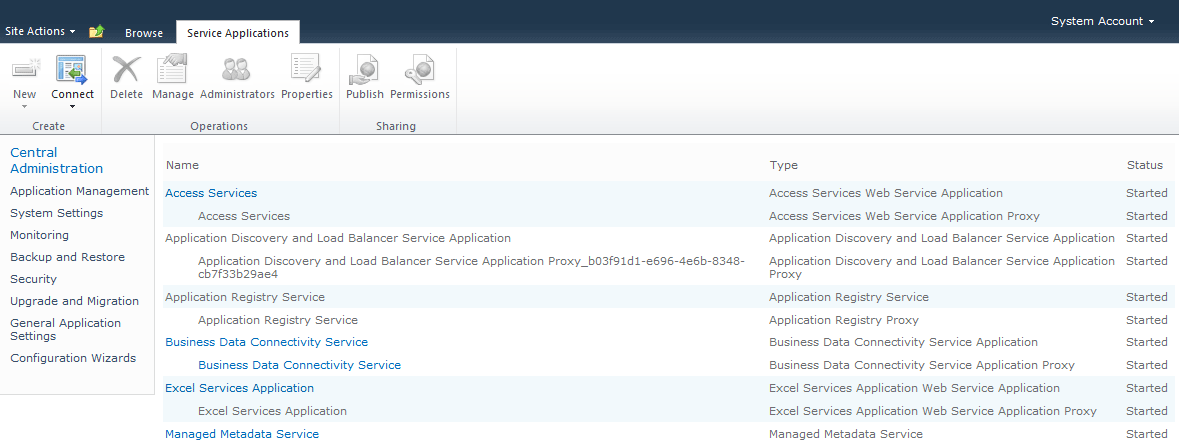
You will often find blogs stating that read operations from the content database are unsupported and that we should use other mechanisms such as SQL Server Reporting Services, SharePoint Designer, Web Services, etc.
Any one of these tools will eventually do a direct read to the content database somehow. What good is having data stored in a database if you can’t read it safely?
So when you read these blogs discouraging to do direct reads into a SharePoint database what they are basically telling you is that you shouldn’t do a direct read because you are not smart enough to know how to do it right.
Here are a sample of the arguments some people have made:
Introduction of locks. This isn’t a bad thing, in fact I want to put a lock while I do a read operation.
Returning wrong information as you may not fully understand the database tables, including how versioning, approval, recyclebin. This isn’t a technical problem preventing you from doing a read. This is a problem with you not understanding the DB schema. So learn it, write a bug free query and problem solved.
Service pack/hot fix installed on SharePoint may change database schema/access. Service packs will most likely wipe the your queries if you save them directly on the content database. The solution for this is to create your own database and save your content queries here, so that service packs or hot fixes will not remove them. You still need to test your query after any update to ensure they are still working as expected.
Microsoft does not support accessing SharePoint database. Fair enough but what benefits do I get when Microsoft supports my installation? Once when I reached out to solve a problem in our production environment we were told, after 6 months of escalations and meeting with their engineers, to install our production environment from scratch. I’m sorry but I don’t see any value in Microsoft supporting my installation.
If your solution can use a Web/Rest, dotNet/SharePoint Object Model then by all means these should be your first choices. But for tools such as SSAS which can’t consume data this way then you are left with no other options.
Do not get discouraged but some of the recommendations out there against this approach, I’ve been writing SharePoint content DB queries in our production environments since the 2001 version and with no ill effects.
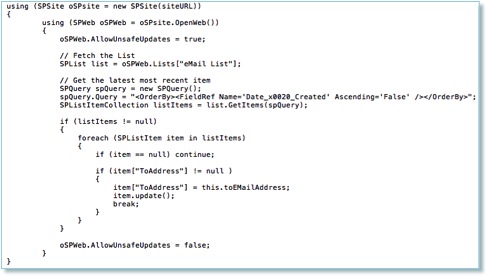
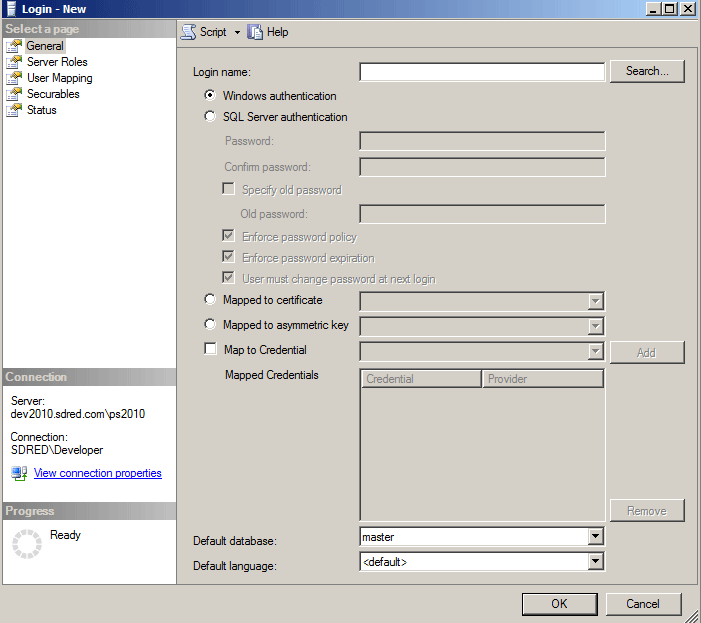
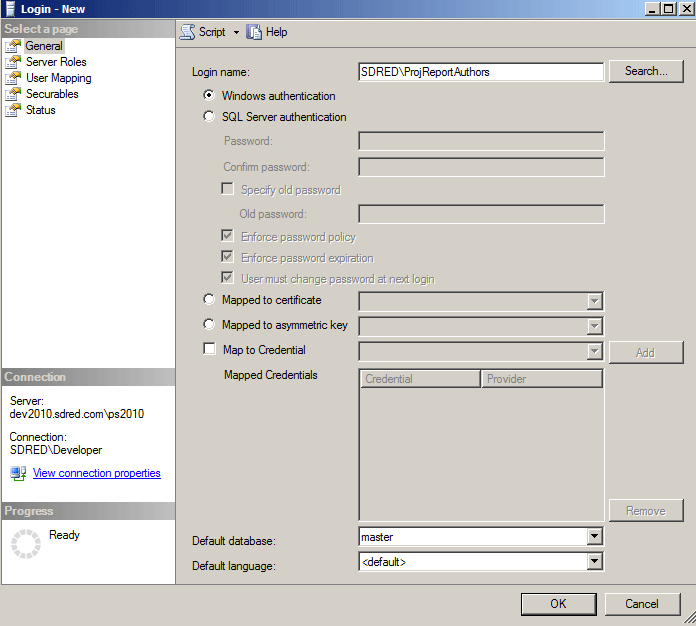
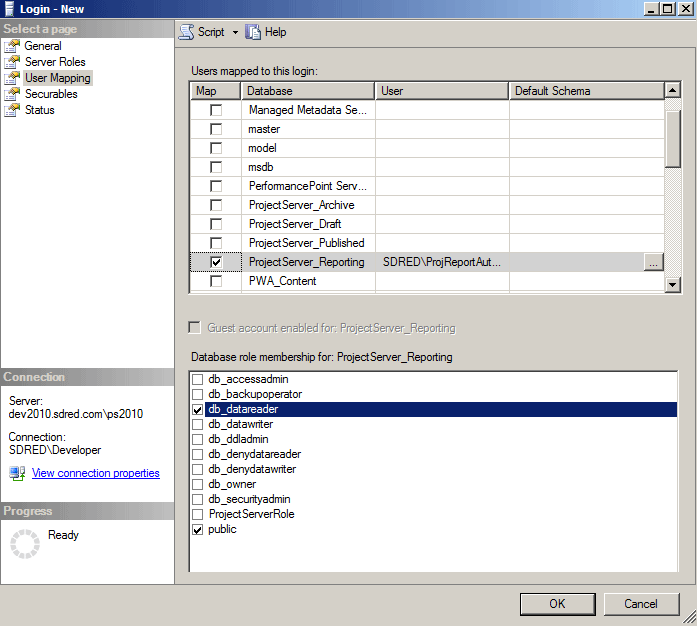
Typically I store my queries as database views (in a different database as noted earlier) but before I can write them I need to determine the corresponding database column name for the SharePoint list column.
A good way to do this is with the help of SharePoint Power Shell where will invoke the cmdlet Get-SPWeb.
As an example I have a collection site called ‘Sales’ and it contains a SharePoint list called ‘Customers’
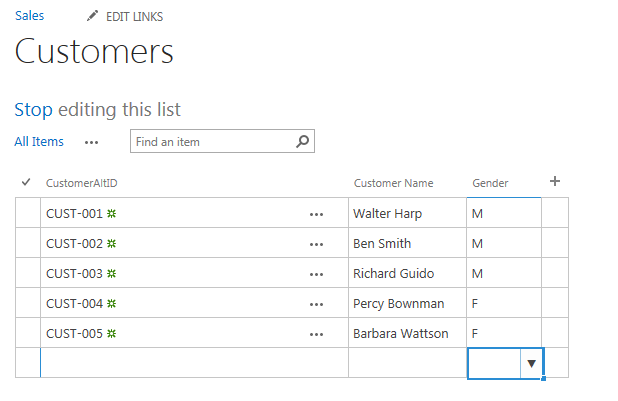
This list contains 3 SharePoint columns
- Title (which I have renamed CustomerAltID)
- Customer Name
- Gender
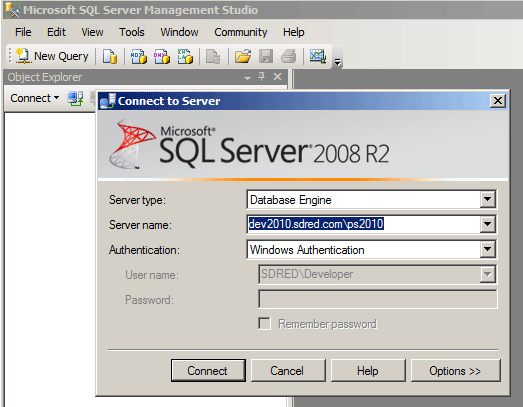
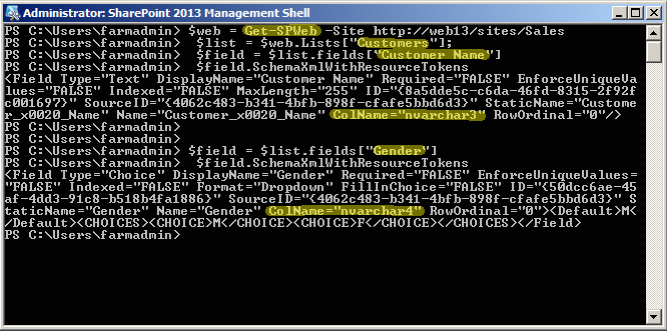
To discover which database columns they were allocated we first launch a SharePoint Management Shell

We then invoke the following commands:
- $web = Get-SPWeb -Site http://web13/sites/Sales
- $list = $web.Lists[“Customers”];
- $field = $list.fields[“Customer Name”]
- $field.SchemaXmlWithResourceTokens
- $field = $list.fields[“Gender”]
- $field.SchemaXmlWithResourceTokens
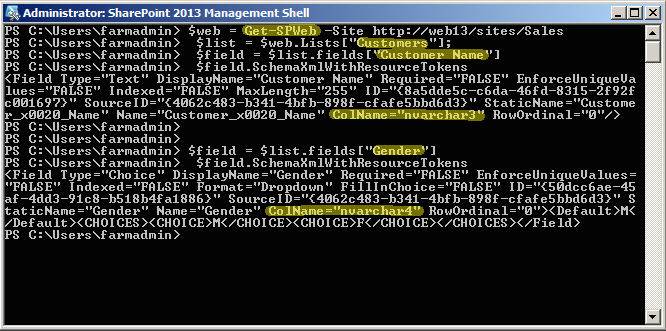
The Get-SPWeb cmdlet returns all subsites that match the scope given by the Identity parameter. I only have one in my SharePoint farm that meets this criteria so I can safely then
analyze the properties of the Web class returned by the cmdlet.
In this case I will use the Lists property to retrieve my ‘Customers’ list in an object of class Microsoft.SharePoint.Client.List
Finally I use the fields property of the List class to obtain the Microsoft.SharePoint.Client.Field object and use its SchemaXmlWithResourceTokens property to look at the XML Schema definition for the field of interest. The value we are looking for is contained in the ‘ColName’ property of the Field Type. This is the database column name we will then use in our SQL queries.
REFERENCES